La extracción de metadatos: Cómo transformar datos no estructurados en información útil
En la era digital, los datos son los reyes, pero no todos los datos son iguales. La extracción de metadatos es el héroe anónimo de la gestión moderna de la información que convierte el contenido bruto y no estructurado en una mina de oro de inteligencia procesable

¿Qué es la extracción de metadatos?
La extracción de metadatos es el proceso de identificar, capturar y organizar información descriptiva sobre contenidos digitales. Es como crear una tarjeta de identificación detallada para cada pieza de información digital, ya sea un vídeo, un documento, una imagen o un archivo de audio.
¿Por qué es importante la extracción de metadatos?
Cada día, las organizaciones generan cantidades ingentes de datos no estructurados. Sin una extracción y gestión adecuadas, estos datos son esencialmente un pajar en el que encontrar la aguja adecuada es casi imposible. La extracción de metadatos transforma este caótico panorama de datos en un recurso bien organizado y con capacidad de búsqueda.
Componentes Clave de la Extracción de Metadatos
1. Tipos de Metadatos
Los metadatos no son uniformes. Suelen clasificarse en varias categorías:
- Metadatos Descriptivos: Identifican y describen un recurso (título, autor, fecha de creación).
- Metadatos Estructurales: Explican cómo se componen los objetos.
- Metadatos Administrativos: Proporciona información para ayudar a gestionar un recurso (tipo de archivo, permisos de acceso).
- Metadatos Técnicos: Captura detalles técnicos sobre la creación de un archivo y sus características técnicas.
2. Técnicas habituales de extracción de metadatos
La extracción de metadatos es un proceso esencial para transformar el contenido multimedia en datos estructurados que permitan realizar búsquedas. Esta tarea aprovecha diversas tecnologías avanzadas, pero puede simplificarse en dos categorías principales: Algoritmos genéricos de aprendizaje automático (ML) y técnicas específicas de cada dominio. Este enfoque destaca los métodos generales al tiempo que muestra herramientas únicas y especializadas utilizadas en la extracción de metadatos.
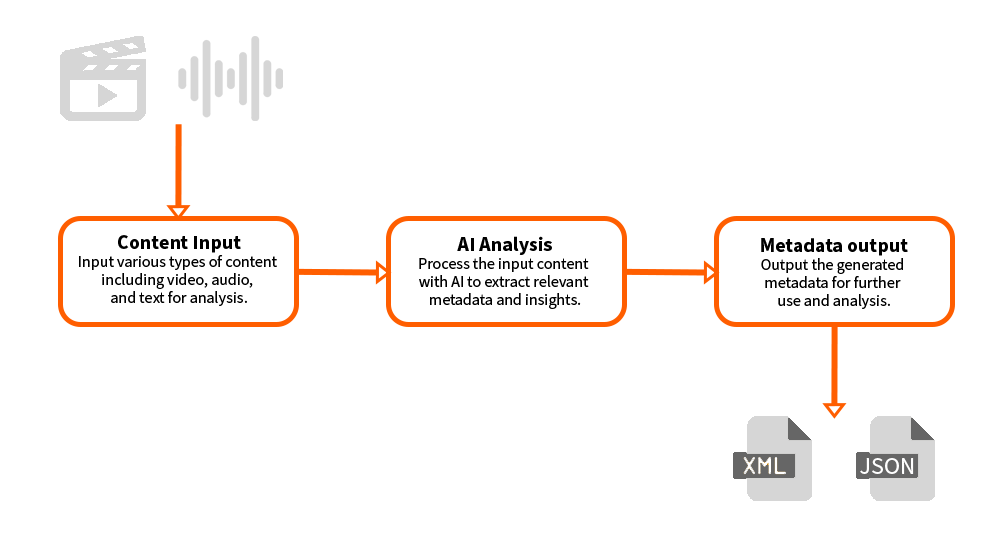
2.1. Algoritmos genéricos de aprendizaje automático en la extracción de metadatos
En el corazón de la extracción de metadatos, el ML proporciona herramientas potentes y flexibles para automatizar la organización y el etiquetado de los datos. Estos algoritmos se utilizan ampliamente para gestionar colecciones multimedia a gran escala. Las técnicas clave son:
- Agrupación: Agrupación automática de contenidos similares, como la categorización de vídeos o imágenes por temas como «deportes» o «entretenimiento».
- Clasificación: Asignación de etiquetas predefinidas al contenido, como etiquetar un vídeo como «noticias» o «documental».
- Recomendación de contenidos: Sugerencia inteligente de contenidos relacionados en función de atributos de metadatos compartidos.
Estos métodos constituyen la base de las técnicas de extracción de metadatos y pueden adaptarse a diversos sectores, como los medios de comunicación, el entretenimiento y el comercio electrónico.
2.2. Técnicas de extracción de metadatos específicas de un dominio
Mientras que el Machine Learning genérico proporciona una base sólida, las técnicas específicas de dominio abordan los retos únicos de los contenidos multimedia. Estos métodos están adaptados para manejar formatos de datos específicos, como audio, vídeo y texto.
- Reconocimiento óptico de caracteres (OCR)
- Lo que hace: El OCR extrae texto de imágenes o fotogramas de vídeo y lo convierte en datos legibles por máquina.
- Casos de uso: Extracción de subtítulos, digitalización de documentos impresos y análisis de texto en pantalla para la indexación de vídeos.
- El porqué es relevante: Garantiza la accesibilidad y la capacidad de búsqueda de los medios visuales.
- Conversión de voz a texto (S2T) o Transcripción
- Lo que hace: Convierte audio hablado en texto, a menudo con funciones como la identificación del locutor y marcas de tiempo.
- Casos de uso: Generación de transcripciones para entrevistas, podcasts y archivos de vídeo.
- El porqué es relevante: Facilita la búsqueda y el análisis de contenidos multimedia, especialmente en sectores como el periodismo y la radiodifusión.
- Procesamiento de lenguaje natural (NLP)
- Lo que hace: Analiza texto para extraer metadatos significativos, como palabras clave, temas y entidades con nombre.
- Casos de uso: Resumir contenidos, mejorar las capacidades de búsqueda y automatizar los flujos de trabajo de etiquetado.
- El porqué es relevante: La NLP transforma el texto en bruto en metadatos procesables, agilizando las operaciones de las organizaciones con gran volumen de contenidos.
Aplicaciones prácticas de la extracción de metadatos
Medios de comunicación y entretenimiento
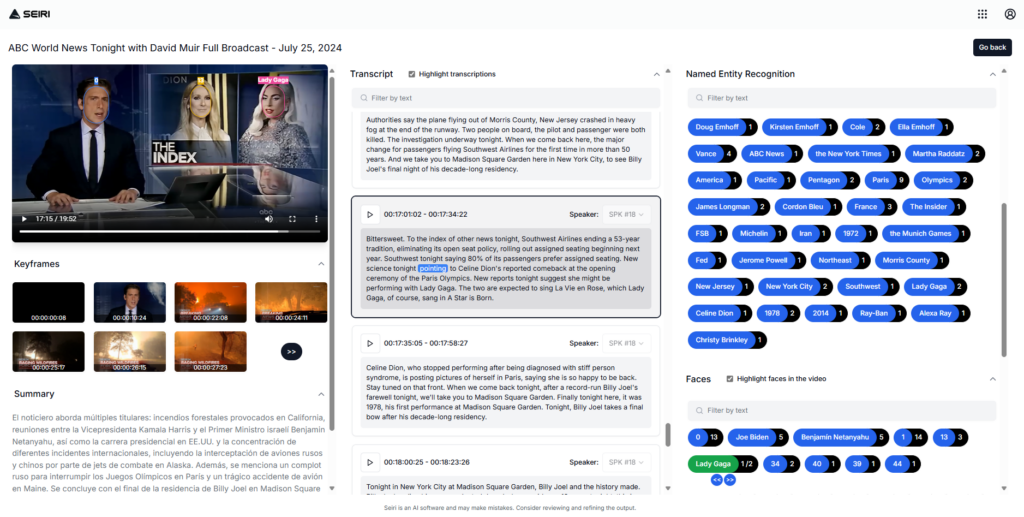
La solución Seiri de Amplify Software muestra el potencial de vanguardia de la extracción de metadatos:
- Transcripción Automática: Convierta el audio en texto preciso, con identificación completa del locutor.
- Navegación interactiva de contenidos: Navegue por los vídeos seleccionando palabras específicas en transcripciones sincronizadas.
- Clasificación avanzada de contenidos: Clasifique automáticamente los contenidos en géneros como noticias, deportes o entretenimiento.
Capacidades avanzadas de extracción
Aprovechando las tecnologías basadas en IA, las herramientas modernas de extracción de metadatos pueden ahora:
- Reconocimiento Facial: Identificar y rastrear individuos en contenidos de vídeo.
- Extracción de palabras clave: Identificar términos esenciales con enlaces de código de tiempo precisos.
- Reconocimiento de entidades nombradas: Categorizar automáticamente fechas, ubicaciones y entidades clave.
- Reconocimiento ópticos de caracteres: Extraer texto de imágenes y detecte logotipos
- Segmentación semántica: Desglosar el contenido por temas para obtener información más detallada.
Aplicaciones sectoriales
Producción audiovisual
- Agilice los flujos de trabajo de postproducción
- Generación automática de subtítulos
- Cree archivos de contenidos ricos y con capacidad de búsqueda
Distribución de contenidos
- Recomendaciones de contenidos específicas
- Desarrollar experiencias de visualización personalizadas
- Mejorar la localización de contenidos
El enfoque Seiri para la extracción de metadatos
Inspirada en la metodología japonesa de las 5S para la organización del lugar de trabajo, la solución Seiri de Amplify Software demuestra el potencial de la extracción de metadatos de nueva generación
Diferenciadores clave
- Precisión: Adaptable a las necesidades específicas del cliente
- Integración: Compatibilidad perfecta con los sistemas de documentación existentes
- Accesibilidad: Interfaz intuitiva para usuarios de todos los niveles técnicos
- Tecnologías avanzadas: Utilización de modelos generativos y procesamiento multimodal
Extracción del máximo valor
El verdadero poder de la extracción de metadatos reside en su capacidad para:
- Reducir drásticamente el trabajo manual
- Mejorar la accesibilidad de los contenidos
- Proporcionar funciones preparadas para el futuro
- Permitir la toma de decisiones basada en datos
Impulse su estrategia de extracción de metadatos
Para maximizar el valor de los metadatos, es crucial adoptar una combinación adaptada de estas técnicas de extracción. Tanto si se centra en mejorar la indexación de vídeos como en automatizar la transcripción o mejorar el descubrimiento de contenidos, estos métodos le ofrecen las herramientas que necesita para mantenerse a la vanguardia en un mundo impulsado por los datos.
¡Explore el poder de las técnicas de extracción de metadatos y transforme hoy mismo su forma de gestionar los contenidos multimedia!
